Repositório de dados
Existem inúmeros repositórios contendo dados hidrológicos no mundo e no Brasil. Alguns exemplos são:
- HidroWeb da ANA;
- Séries históricas do ONS;
- Dados do CPRM;
- Dados do INMET.
Obtenção de dados “tradicional”
Uma maneira de obter dados hidrológicos é simplesmente acessando de algum site oficial. Geralmente, o arquivo obtido baixado está no formato .csv, .txt ou .xls (excel) - esse último sendo menos comum. No próprio portal da ANA tem a opção de baixar os dados diretamente se souber a estação em questão ou utilizando um mapa dinâmico.
Fazemos o exemplo abaixo para a estação 60435000. Ao baixar o arquivo, é importante entender como ele está salvo, para isso podemos abrir o arquivo pelo bloco de notas por exemplo. O arquivo em questão é mostrado na figura abaixo
Uma maneira de obter dados é simplesmente baixando eles de algum site oficial. Geralmente o arquivo baixado está no formato .csv, .txt ou .xls (excel) - esse último sendo menos comum. No próprio portal da ANA tem a opção de baixar os dados diretamente se souber a estação em questão (https://www.snirh.gov.br/hidroweb/serieshistoricas) ou utilizando um mapa dinâmico (https://www.snirh.gov.br/hidroweb/mapa). Fazemos o exemplo abaixo para a estação 60435000. Ao baixar o arquivo, é importante entender como ele está salvo, para isso podemos abrir o arquivo pelo bloco de notas por exemplo. O arquivo em questão é mostrado na figura abaixo
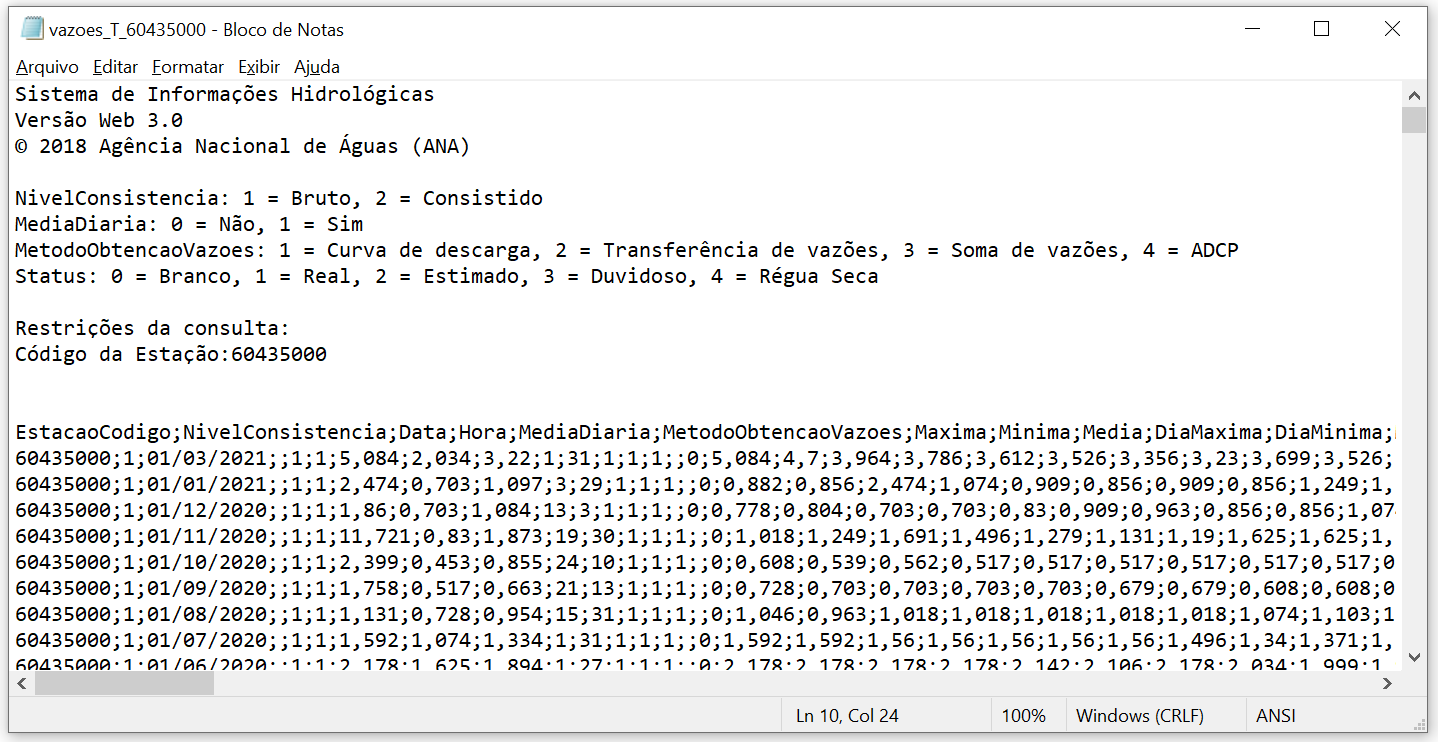
É possível perceber alguns detalhes importantes. As primeiras 13 linhas contém informações sobre o sistema em sí e a estação, mas os dados medidos começam de fato na linha 14. O separador de cada coluna é um “;” e os decimais são separados por “,”. Agora já temos as informações necessárias para acessar esses dados pelo R. Usamos aqui a função read.table(), também é possível utilizar a função read.csv(), ambas fazem a mesma coisa, apenas alteram os argumentos pré definidos (que podem ser trocados).
dados_ANA <- read.table(file = "dados/vazoes_T_60435000.txt",
skip = 13,
header = T,
sep = ";",
dec = ",")Agora podemos ver quais colunas existem nesse dataframe dentro do próprio R e tentar entender ele melhor também!
colnames(dados_ANA) [1] "EstacaoCodigo" "NivelConsistencia"
[3] "Data" "Hora"
[5] "MediaDiaria" "MetodoObtencaoVazoes"
[7] "Maxima" "Minima"
[9] "Media" "DiaMaxima"
[11] "DiaMinima" "MaximaStatus"
[13] "MinimaStatus" "MediaStatus"
[15] "MediaAnual" "MediaAnualStatus"
[17] "Vazao01" "Vazao02"
[19] "Vazao03" "Vazao04"
[21] "Vazao05" "Vazao06"
[23] "Vazao07" "Vazao08"
[25] "Vazao09" "Vazao10"
[27] "Vazao11" "Vazao12"
[29] "Vazao13" "Vazao14"
[31] "Vazao15" "Vazao16"
[33] "Vazao17" "Vazao18"
[35] "Vazao19" "Vazao20"
[37] "Vazao21" "Vazao22"
[39] "Vazao23" "Vazao24"
[41] "Vazao25" "Vazao26"
[43] "Vazao27" "Vazao28"
[45] "Vazao29" "Vazao30"
[47] "Vazao31" "Vazao01Status"
[49] "Vazao02Status" "Vazao03Status"
[51] "Vazao04Status" "Vazao05Status"
[53] "Vazao06Status" "Vazao07Status"
[55] "Vazao08Status" "Vazao09Status"
[57] "Vazao10Status" "Vazao11Status"
[59] "Vazao12Status" "Vazao13Status"
[61] "Vazao14Status" "Vazao15Status"
[63] "Vazao16Status" "Vazao17Status"
[65] "Vazao18Status" "Vazao19Status"
[67] "Vazao20Status" "Vazao21Status"
[69] "Vazao22Status" "Vazao23Status"
[71] "Vazao24Status" "Vazao25Status"
[73] "Vazao26Status" "Vazao27Status"
[75] "Vazao28Status" "Vazao29Status"
[77] "Vazao30Status" "Vazao31Status"
[79] "X" A seguir puxaremos o mesmo dado porém diretamente da internet, utilizando o que chamamos de webservice. Isso facilita muito a criação de códigos mais automatizados em que não é necessário ficar baixando os dados um a um.
Obtenção via webservice
Ser capaz de obter informações hidrológicas de forma gratuita diretamente da internet, algo conhecido como “webscraping”, representa um ganho significativo de eficiência no desenvolvimento de estudos e projetos de hidrologia, recursos hídricos, e áreas afins.
Essa possibilidade vem se tornando cada vez mais comum nos dias de hoje. Por exemplo, a Agência Nacional de Águas e Saneamento Básico (ANA), o Operador Nacional do Sistema Elétrico (ONS), e outras instituições no Brasil e no exterior disponibilizam alguns de seus dados por meio do chamado webservice.
Em essência, o webservice é apenas um site que contém os dados. Porém, esses dados estão organizados de uma maneira bem específica, de forma que para que seja possível obtê-los de forma eficiente, é imprescindível que essa organização seja bem entedida. Aqui neste curso introdutório, vamos focar nossas atividades no webservice da ANA, que se encontra disponível por meio do url http://telemetriaws1.ana.gov.br/ServiceANA.asmx.
Quando acessamos esse endereço, somos levados para a página abaixo,
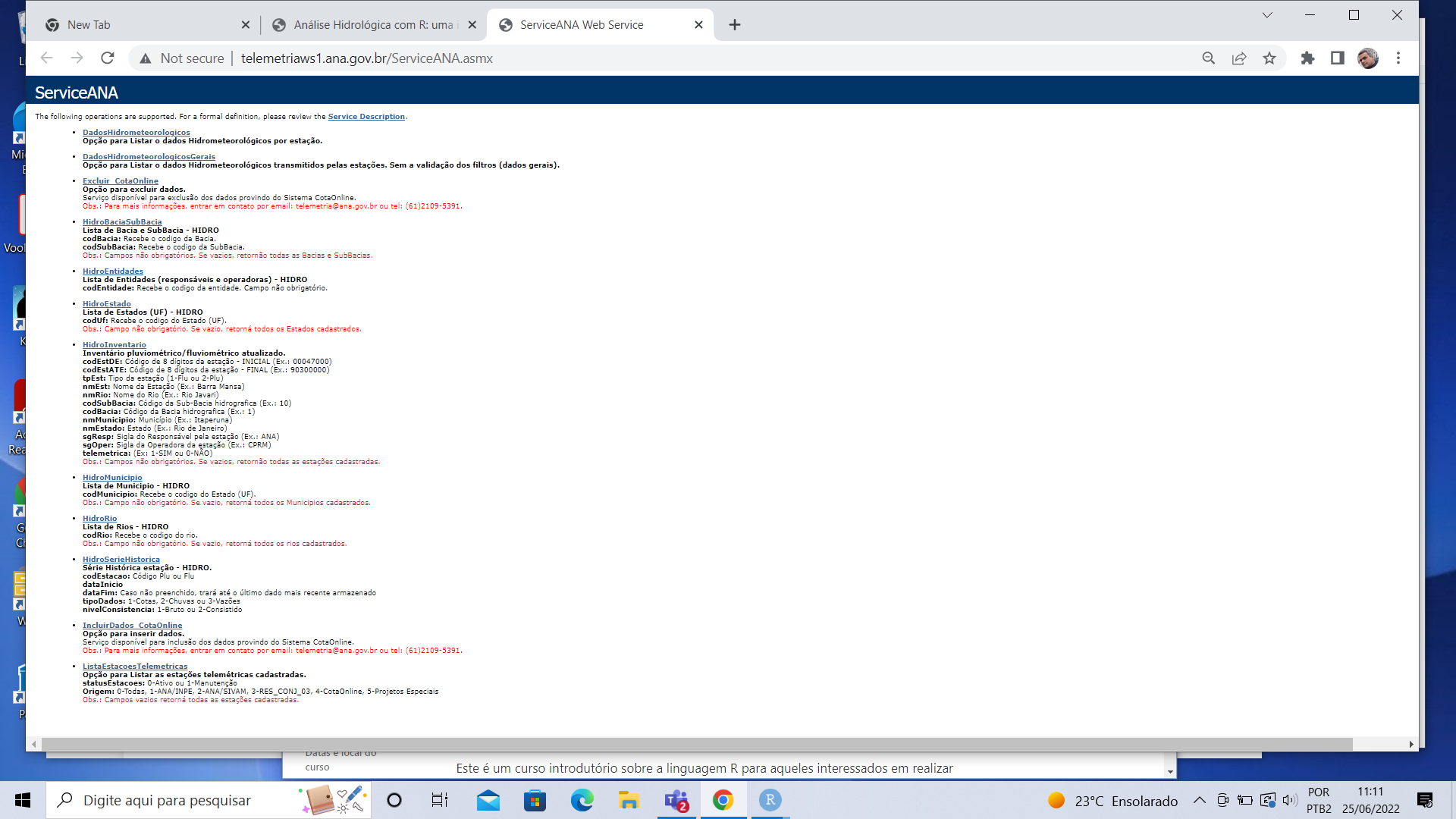
Se dermos um zoom na figura, podemos verificar todas as informações que estão disponíveis no webservice, tais como “dados hidrometeorológicos”, “dados hidrometeorológicos gerais”, “lista de estações telemétricas”, “Cotas”, “inventário”, “rios”, “série histórica”, entre outras.
Nesse mesmo site, pode-se acessar um arquivo em formato pdf com detalhes sobre o sistema como um todo, e com o que se pode obter dentro dele http://telemetriaws1.ana.gov.br/Telemetria1ws.pdf! Esse arquivo é essencial para entendermos como os dados estão disponíveis e como podemos acessá-los.
Esse documento nos informa que os dados hidrológicos da ANA estão disponibilizados no formato XML (“Extended Markup Language”), de forma que precisamos aprender como acessar e manipular as informações disponibilizados nesse formato. Mas discutiremos apenas o básico neste curso, sem nos profundarmos muito. Porém se você deseja saber mais sobre webscraping e usufruir de várias de suas possibilidade, sugerimos que procure se aprofundar mais nesse tema.
Para acessar dados do tipo XML dentro do R, utilizamos um pacote já criado, chamado XML. Lembrando que caso não tenhamos instalado ele ainda, precisamos o fazer com o install.packages(). Em seguida precisamos apenas carregar na seção utilizando library() como escrito abaixo. Além desse pacote, também utilizaremos algumas partes do pacote lubridate para trabalharmos com datas.
Lista das Estações Telemétricas da ANA
Começaremos nossas atividades acessando os dados das estações telemétricas desse sistema. Pode-se perceber olhando para o próprio site, que são necessários dois parâmetros para pesquisar as estações. O primiero chama-se “statusEstacoes”, que pode ser 0, que significa estação ativa, ou 1, que representa estação em manutenção. O segundo parâmetro é chamado de “Origem”, podendo variar entre 0 e 5. Se olharmos o arquivo em formato pdf mencioando acima, vamos ver que se deixarmos o “statusEstacoes” em branco, serão retornadas as informações de todas as estações do sistema, que é exatamente o que queremos agora.
Sendo assim, se colocarmos no nosso navegador o seguinte url: http://telemetriaws1.ana.gov.br/ServiceANA.asmx/ListaEstacoesTelemetricas?statusEstacoes=&origem=, teremos acesso ao arquivo XML com a informação de todas as estações telemétricas.
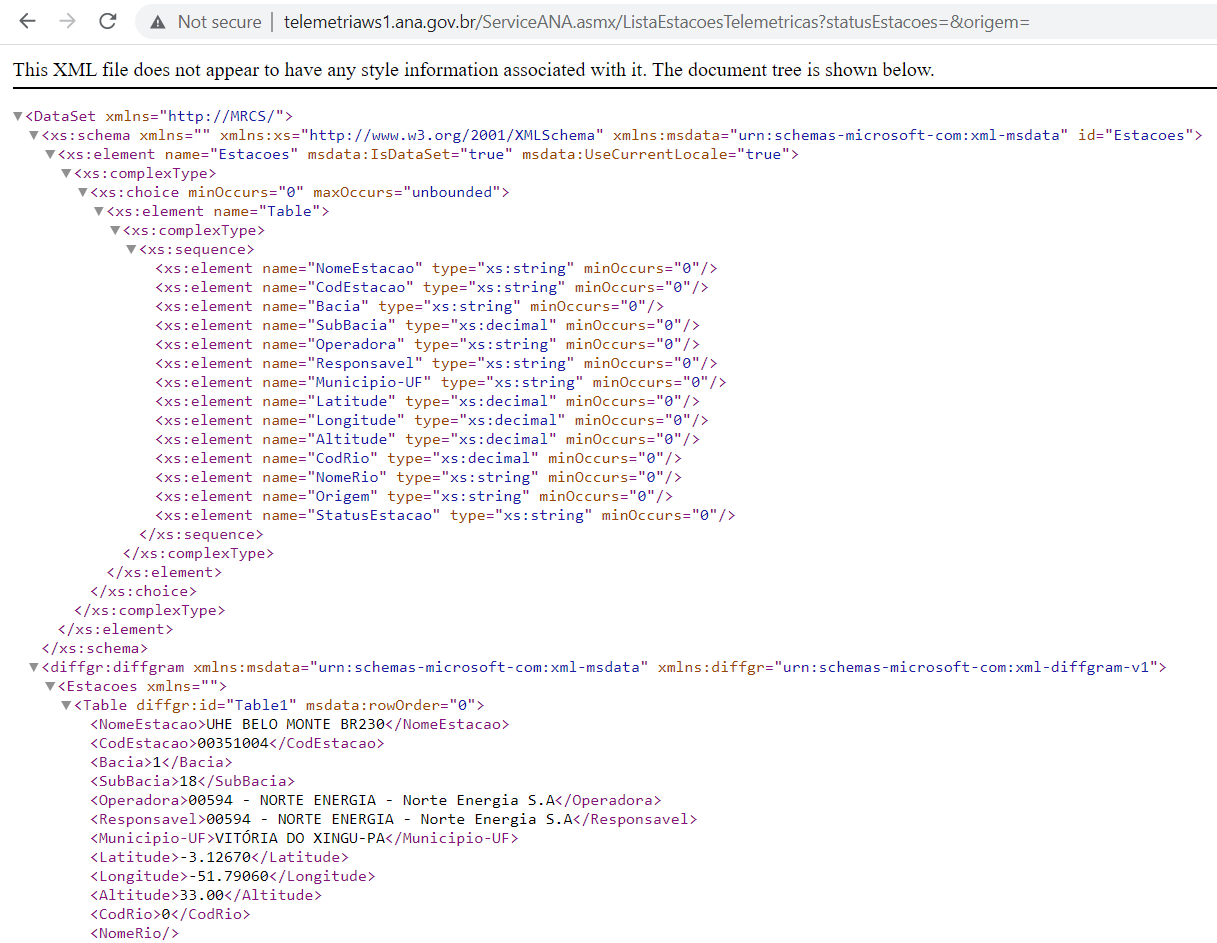
Para que tenhamos cesso a essas informações nesse mesmo formato no RStudio, teremos que fazer uso de um pacote chamado “XML”, que contém a função denominada xmlParse(). Essa função é capaz de ler um arquivo do tipo XML e gerar uma estrutura no R similar ao que aparece na imagem acima (formato de “árvore”). A função exige que informemos um argumento obrigatório, que é o url a ser utilizado, e permite ainda que passemos um argumento opcional, que é a codificação do arquivo (do inglês encoding). Usualmente no Brasil, utilizamos o “UTF-8” para poder utilizar nossos acentos (mas lembre-se que essa parte é um outro mundo no R e não entraremos com maiores detalhamentos). Quando um pacote já está carregado dentro do R, não precisamos escrever ele antes da função - isso, porém, pode ser uma boa prática para deixar o código mais fácil de ler (uma vez que qualquer leitor entenderia que a funçção xmlParse() pertence ao pacote XML uma vez que está escrito XML:: antes da função!
Olha o nosso código um pouco. Percebe que invés de digitar diretamente o url para acesso, quebramos ele em várias partes e juntamos com a função paste0(). Fizemos isso para ficar mais fácil de mudar algo depois. Caso quisermos utilizar outro valor em “statusEstacoes” ou em “Origem”, basta mudarmos os objetos criados e o resto do código continua igual! Ao chamar o url_parse no console, verá uma imagem similar ao site quando abrimos o url.
Para puxar agora as informações dessas estações, precisamos entender melhor o arquivo original no formato XML. De maneira resumida, arquivos no formato XML ou HTML possuem estruturas que são definidas entre “< >”. Ao mexer no url que nos dá todas as estações, percebe-se que todos os dados de cada estação são precedidos por um elemento chamado “Table” (dentro do “<>”). Porém, queremos os nodes que estão associados a esses “Tables” (tabelas). Para isso, samos a função getNodeSet(). Com os argumentos dessa função sendo primeiro o objeto criado no R depois de ter feito um xmlParse() e o segundo argumento sendo “//Table” (lembrar de colocar essas duas barras)
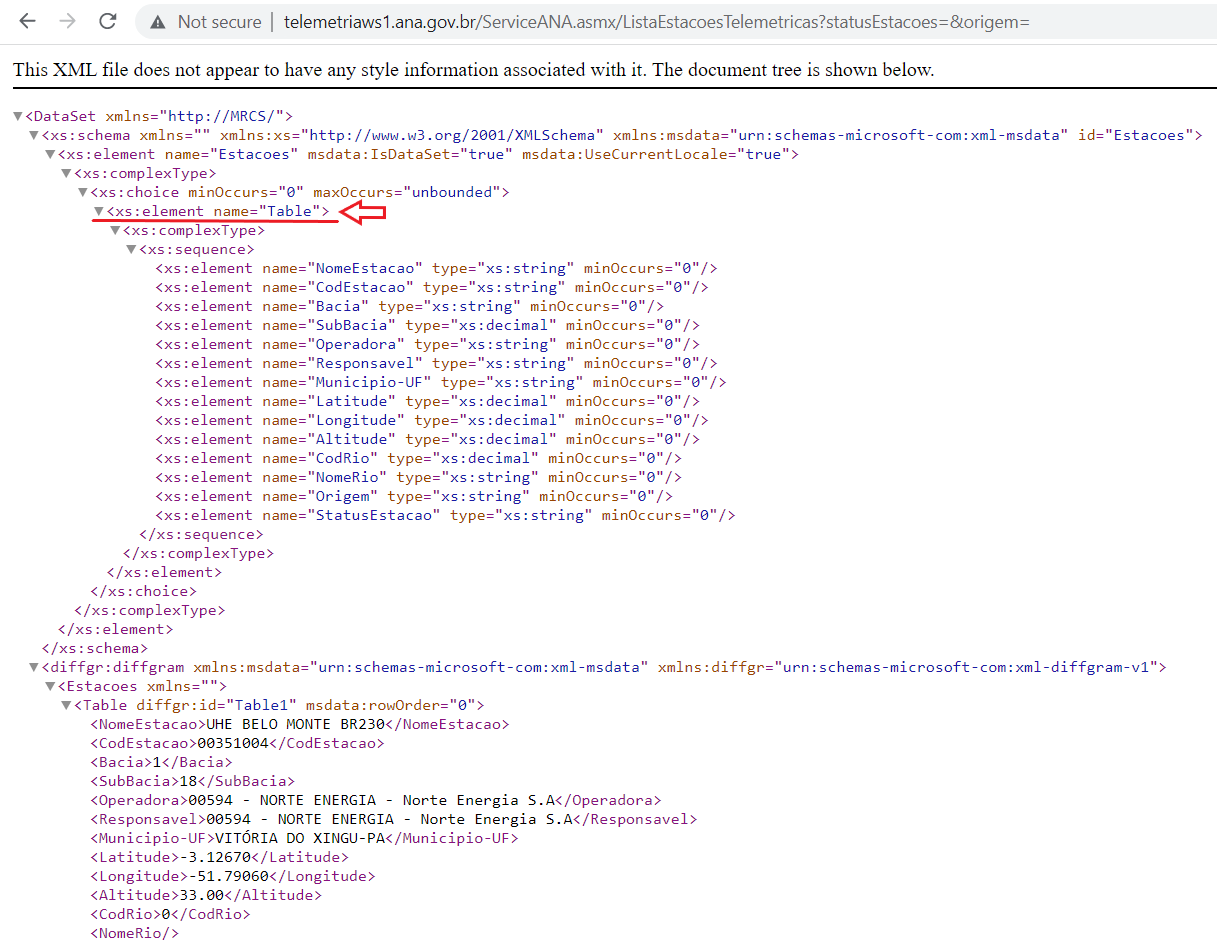
A próxima etapa agora é transformar esse arquivo em algo que estamos mais acostumados a mexer dentro do R. Boas opções são dataframes e listas. Como não aprendemos a mexer muito com listas, vamos transformar nosso objeto em um dataframe. Para isso utilizamos a função xmlToDataFrame().
nodes_doc <- XML::getNodeSet(url_parse, "//Table")
cadastro_estacoes <- XML::xmlToDataFrame(nodes = nodes_doc)Agora podemos fazer as manipulações que já aprendemos anteriormente (com dataframe ficou fácil!). Por exemplo, se quisermos selecionar apenas as estações de Brasília, escrevemos o código abaixo. O “Municipio-UF” é apenas uma das colunas do dataframe, podemos filtrar com base em qualquer outra também. Vemos então a estrutura desse dataframe criado, usando a função str(), e as primeiras 5 linhas delem usando a função head().
'data.frame': 56 obs. of 14 variables:
$ NomeEstacao : chr "ANA SEDE - TELEMÉTRICA" "ESTACAO TESTE_PLU" "RIBEIRÃO PALMEIRAS" "SONHEM" ...
$ CodEstacao : chr "01547079" "09999999" "20000950" "20001050" ...
$ Bacia : chr "6" "6" "2" "2" ...
$ SubBacia : chr "60" "60" "20" "20" ...
$ Operadora : chr "00001 - ANA - Agência Nacional de Águas " "00001 - ANA - Agência Nacional de Águas " "00190 - ADASA-DF - Agência Reguladora de Águas e Saneamento - DF" "00190 - ADASA-DF - Agência Reguladora de Águas e Saneamento - DF" ...
$ Responsavel : chr "00001 - ANA - Agência Nacional de Águas " "00001 - ANA - Agência Nacional de Águas " "00190 - ADASA-DF - Agência Reguladora de Águas e Saneamento - DF" "00190 - ADASA-DF - Agência Reguladora de Águas e Saneamento - DF" ...
$ Municipio-UF : chr "BRASÍLIA-DF" "BRASÍLIA-DF" "BRASÍLIA-DF" "BRASÍLIA-DF" ...
$ Latitude : chr "-15.81810" "-15.81810" "-15.52810" "-15.52310" ...
$ Longitude : chr "-47.94500" "-47.94500" "-47.74190" "-47.81580" ...
$ Altitude : chr "1150.00" "1150.00" "0.00" "0.00" ...
$ CodRio : chr "0" "0" "20003000" "20030000" ...
$ NomeRio : chr "" "" "RIBEIRÃO PALMEIRAS" "RIO SONHEM" ...
$ Origem : chr "RHN" "Açudes Semiárido" "Setores Regulados" "Setores Regulados" ...
$ StatusEstacao: chr "Ativo" "Ativo" "Ativo" "Ativo" ...head(estacoes_bsb) NomeEstacao CodEstacao Bacia SubBacia
1 ANA SEDE - TELEMÉTRICA 01547079 6 60
2 ESTACAO TESTE_PLU 09999999 6 60
3 RIBEIRÃO PALMEIRAS 20000950 2 20
4 SONHEM 20001050 2 20
5 CONTAGEM - VC 201 20001200 2 20
6 RIBEIRÃO SANTA RITA 42450050 4 42
Operadora
1 00001 - ANA - Agência Nacional de Águas
2 00001 - ANA - Agência Nacional de Águas
3 00190 - ADASA-DF - Agência Reguladora de Águas e Saneamento - DF
4 00190 - ADASA-DF - Agência Reguladora de Águas e Saneamento - DF
5 00190 - ADASA-DF - Agência Reguladora de Águas e Saneamento - DF
6 00190 - ADASA-DF - Agência Reguladora de Águas e Saneamento - DF
Responsavel
1 00001 - ANA - Agência Nacional de Águas
2 00001 - ANA - Agência Nacional de Águas
3 00190 - ADASA-DF - Agência Reguladora de Águas e Saneamento - DF
4 00190 - ADASA-DF - Agência Reguladora de Águas e Saneamento - DF
5 00190 - ADASA-DF - Agência Reguladora de Águas e Saneamento - DF
6 00190 - ADASA-DF - Agência Reguladora de Águas e Saneamento - DF
Municipio-UF Latitude Longitude Altitude CodRio
1 BRASÍLIA-DF -15.81810 -47.94500 1150.00 0
2 BRASÍLIA-DF -15.81810 -47.94500 1150.00 0
3 BRASÍLIA-DF -15.52810 -47.74190 0.00 20003000
4 BRASÍLIA-DF -15.52310 -47.81580 0.00 20030000
5 BRASÍLIA-DF -15.50080 -47.85420 0.00 20050000
6 BRASÍLIA-DF -15.58560 -47.33330 870.00 42250100
NomeRio Origem StatusEstacao
1 RHN Ativo
2 Açudes Semiárido Ativo
3 RIBEIRÃO PALMEIRAS Setores Regulados Ativo
4 RIO SONHEM Setores Regulados Ativo
5 RIBEIRÃO DA CONTAGEM RHN Ativo
6 RIBEIRÃO SANTA RITA RHN AtivoLembrando que isso tudo nos dá apenas a lista com informações sobre as estações telemétricas. Para de fato termos acesso aos dados dessas estações, precisamos acessar outro url e fazer mais alguns códigos!
Idealmente, se a gente quiser ficar sempre puxando diferentes informações e não ficar precisando rodar linha por linha de código, podemos juntar tudo isso em uma função. Para a nossa função, deixaremos o processo um pouco melhor. Primeiro definiremos que a função precisa de 3 parâmetros (o status da estação, a origem e qual Unidade Federativa do Brasil queremos). Após puxar os dados em XML e transformar tudo em um dataframe, fazemos aqui algo novo - criamos uma coluna chamada “UF” contendo apenas as últimas duas letras do Município (isos porque no arquivo original, as duas últimas letras são as siglas da UF).
ANA_info <- function(status_codigo = "",
origem_codigo = "",
UF_fun = "DF"){
# Essas etapas foram vistas anteriormente
url_base <- paste0("http://telemetriaws1.ana.gov.br/ServiceANA.asmx/ListaEstacoesTelemetricas?",
"statusEstacoes=", status_codigo,
"&origem=", origem_codigo)
url_parse <- XML::xmlParse(url_base, encoding = "UTF-8")
nodes_doc <- XML::getNodeSet(url_parse, "//Table")
cadastro_estacoes <- XML::xmlToDataFrame(nodes = nodes_doc)
# Aqui criamos uma coluna no dataframe apenas com nomes das UFs
cadastro_estacoes$UF <- substr(cadastro_estacoes$`Municipio-UF`,
nchar(cadastro_estacoes$`Municipio-UF`) - 1,
nchar(cadastro_estacoes$`Municipio-UF`))
estacoes_UF <- dplyr::filter(cadastro_estacoes, `UF` == UF_fun)
return(estacoes_UF)
}Podemos simplesmente testar essa função criada chamando a função e atribuindo para um objeto qualquer (chamamos aqui de “teste”) seu resultado. Em seguida falamos para o R printar as colunas desse dataframe.
# Testar a função feita!
teste <- ANA_info()
colnames(teste) [1] "NomeEstacao" "CodEstacao" "Bacia" "SubBacia"
[5] "Operadora" "Responsavel" "Municipio-UF" "Latitude"
[9] "Longitude" "Altitude" "CodRio" "NomeRio"
[13] "Origem" "StatusEstacao" "UF" Dados Hidrometeorológicos da ANA
Para acessar os dados hidrometeorológicos nesse webservice, temos outro url: http://telemetriaws1.ana.gov.br/ServiceANA.asmx?op=DadosHidrometeorologicos. Nele, vemos que são necessárias agora três parâmetros para fazermos uma busca: o “codEstacao” (que a gente pegou na parte anterior!), a “dataInicio” e a “dataFim”. Do mesmo jeito de antes, vamos definir um objeto para cada parâmetro e depois criar um url baseado nesses parâmetros. Em seguida fazemos um xmlParse() e pegamos as informações contidas nos nodes com o getNodeSet(). Por último, transformamos isso em um dataframe. Dessa vez, podemos fazer a função direto ja!
dados_ANA <- function(cod_estacao = "",
data_inicio = "01/01/2020",
data_fim = Sys.Date()){
# Puxar dados do url e transformar em dataframe
url_base <- paste0("http://telemetriaws1.ana.gov.br/ServiceANA.asmx/DadosHidrometeorologicos?",
"codEstacao=", cod_estacao,
"&dataInicio=", data_inicio,
"&dataFim=", data_fim)
url_parse <- XML::xmlParse(url_base, encoding = "UTF-8")
node_doc <- XML::getNodeSet(url_parse, "//DadosHidrometereologicos")
dados_estacao <- XML::xmlToDataFrame(nodes = node_doc)
return(dados_estacao)
}A partir da função que criamos anteriormente, para puxar as informações das estações, podemos ver os códigos de todas as estações. Um exemplo é a FAL, da própria UnB. Seu código é 60478482 - podemos usar ele na nossa nova função “dados_ANA”. Para ver o que essa função criada retorna, podemos pedir ao R as primeiras 6 linhas desse dataframe.
dados_FAL <- dados_ANA(cod_estacao = 60478482)
head(dados_FAL) CodEstacao DataHora Vazao Nivel Chuva
1 60478482 2024-05-31 14:00:00 0.00
2 60478482 2024-05-31 13:45:00 0.00
3 60478482 2024-05-31 13:30:00 0.00
4 60478482 2024-05-31 13:15:00 0.00
5 60478482 2024-05-31 13:00:00 0.00
6 60478482 2024-05-31 12:45:00 0.00Percebemos aqui um “problema”. A data e a hora estão na mesma coluna e idealmente queremos deixar em colunas separadas (uma contendo a data e outra contendo as horas). Então iremos adicionar dentro da nossa função, mais um comando para fazer essa separação. Um jeito simples (mas não o único) de fazer isso é selecionando os primeiros 10 caracteres como sendo os de data e os últimos 8 como sendo de hora - porque a data sempre vai estar no formato “dia/mes/ano” e o horário em “hora:minuto:segundo”. Podemos também reorganizar as colunas do jeito que quisermos. Abaixo está essa nova função mais organizada.
dados_ANA <- function(cod_estacao = "",
data_inicio = "01/01/2020",
data_fim = Sys.Date()){
# Puxar dados do url e transformar em dataframe
url_base <- paste0("http://telemetriaws1.ana.gov.br/ServiceANA.asmx/DadosHidrometeorologicos?",
"codEstacao=", cod_estacao,
"&dataInicio=", data_inicio,
"&dataFim=", data_fim)
url_parse <- XML::xmlParse(url_base, encoding = "UTF-8")
node_doc <- XML::getNodeSet(url_parse, "//DadosHidrometereologicos")
dados_estacao <- XML::xmlToDataFrame(nodes = node_doc)
# Separar data e hora
dados_estacao$Data <- substr(dados_estacao$DataHora, 1, 10)
dados_estacao$Hora <- substr(dados_estacao$DataHora, 12, 19)
# Re-organizar a ordem das colunas do dataframe dados_estacao
dados_estacao <- dados_estacao[,c(1, 6, 7, 3, 4, 5)]
return(dados_estacao)
}Chamamos novamente essa função (agora atualizada) para rodar a estação da FAL. Em seguida printamos no R apenas as primeiras 6 linhas desse dataframe.
# Rodar a função para a estação da FAL
dados_FAL <- dados_ANA(cod_estacao = 60478482)
head(dados_FAL) CodEstacao Data Hora Vazao Nivel Chuva
1 60478482 2024-05-31 14:00:00 0.00
2 60478482 2024-05-31 13:45:00 0.00
3 60478482 2024-05-31 13:30:00 0.00
4 60478482 2024-05-31 13:15:00 0.00
5 60478482 2024-05-31 13:00:00 0.00
6 60478482 2024-05-31 12:45:00 0.00Aqui rodamos a função apenas para uma estação. Mas se quisermos rodar para várias estações, basta utilizar um loop (for) ou até mesmo a função lapply do R (mais rápido!).
Série Histórica
Outro local do HidroWeb da ANA que possui dados hidrológicos relevantes é na seção de série histórica, disponível online em: http://telemetriaws1.ana.gov.br/ServiceANA.asmx?op=HidroSerieHistorica. Para puxar esse arquivo dentro do R é possível fazer algo similar ao feito acima. Nessa seção, porém, são necessários 5 argumentos:
- codEstacao (código da estação);
- dataInicio (primeira data em que se quer os dados);
- dataFim (última data em que se quer os dados);
- tipoDados (podendo ser cotas, 1, chuvas, 2, ou vazões, 3);
- nivelConsistencia (podendo ser Bruto, 1, ou consistido, 2).
Primeiro então criamos objetos contendo essas informações necessárias para entrar no url da série histórica.
cod_estacao <- 60435000
data_inicio <- "01/01/1800"
data_fim <- Sys.Date()
tipo_dados <- 3
nivel_consist <- 1Em seguida, esses objetos são utilizados para criar um url para podermos acessar os dados do HidroWeb. Após é feito o mesmo que a cima em outros portais dentro do portal da ANA, fazendo então um XML::xmlParse(), seguido por um XML::getNodeSet() e XML::xmlToDataFrame(). Diferentemente do que foi feito anteriormente, não foi feita aqui a separação da coluna de data em duas, uma contendo a data e outra contendo a hora. Na coluna de Data é feita a transformação de character para Date de modo que possamos fazer algumas operações com ela depois.
# Puxar dados do url e transformar em dataframe
url_base <-
paste0("http://telemetriaws1.ana.gov.br/ServiceANA.asmx/",
"HidroSerieHistorica?",
"codEstacao=", cod_estacao,
"&dataInicio=", data_inicio,
"&dataFim=", data_fim,
"&tipoDados=", tipo_dados,
"&nivelConsistencia=", nivel_consist)
url_parse <- XML::xmlParse(url_base, encoding = "UTF-8")
node_doc <- XML::getNodeSet(url_parse, "//SerieHistorica")
dados_estacao <- XML::xmlToDataFrame(nodes = node_doc)É interessante lembrar um pouco como funciona esse formato de datas aqui. As datas podem vir de inúmeras formas diferentes de algum banco de dados. Elas podem vir com “dia - mês - ano”, com o ano podendo ser escrito com todos os dígitos (2022) ou apenas os últimos dois (22). Outra coisa que pode ser alterada é a ordem (“dia - mês - ano” ou “ano - mês - dia” ou qualquer variação desses três). Ainda podemos encontrar em bases de dados o mês escrito por extenso ou abreviado como “01/Jan/1990”. Isso sem contar com o separador dessas datass (“/”, “-”, um espaço em branco…). Podemos definir isso dentro da função as.Date(), utilizando como argumento a seguinte convenção:
- %Y para anos com quatro dígitos;
- %y para anos com dois dígitos;
- %d para os dias (dígitos de 1 a 31);
- %m para os meses (dígitos de 1 a 12);
- %b para meses no formato abreviado em inglês (Jan, Feb, …);
- %B para meses no formato por extenso em inglês (January, February, …).
Essa função do R possui um argumento que irá ficar tentando diversos formatos diferentes e tomará como verdade o primeiro que não retornar valores NA - porém, para formatos específicos (e se já sabemos qual é), pode ser melhor já deixar isso explícito em seu código.
as.Date("2021-11-01", format = "%Y-%m-%d")[1] "2021-11-01"as.Date("01/Jan/70", format = "%d/%b/%y")[1] "1970-01-01"Nesse arquivo temos a necessidade de uma nova etapa. Ao olhar um pouco como os dados estão oganizados, percebemos que existem 78 colunas. Ao invés dos dados de vazão estarem todos em uma mesma coluna, eles estão espaçados por coluna, contendo 1 mês completo para cada linha do dataframe. Isso é um pouco problemático, pois ao puxarmos todas as 31 colunas de dados, estaremos puxandos datas inexistentes como dia 31 de fevereiro. O que fazemos no código abaixo é aplicar (usando a função sapply) uma função para cada linha dos dados da série histórica, e portanto para cada mês. Para cada linha, puxaremos apenas a parte da data contendo o ano e o mês, e em seguida colaremos os valores de 1 a 31 neles. Ao transformarmos esses caracteres em data, utilizando o as.Date, o R fara uma coerção, como comentado anteriormente. Tudo aquilo que ee não conseguir colocar no formato de datas (como o dia 31 de fevereiro), sera retornado como NA. Assim teremos um vetor com as datas corretas, e as dadtas fictícias que criamos e que não existem, estarão como NA.
Em seguida puxamos os dados. Esses podem vir apenas como a transposta das colunas correspondentes, que são as colunas 16 até a 46. Após pegar a transposta dessas colunas de cada linha de data, concatenamos isso em um vetor e transformamos no formato numérico. Sempre deixar seu código pensando em contas matriciais é muito útil (como pegar a transposta), pois o computador consegue fazer essas contas de forma muito eficiente. É extremamente interessante notar que sempre temos diferentes formas de fazer um código, isso vai variar muito com a lógica de cada programador e esse é apenas um exemplo de como podemos pegar esses dados da ANA.
Dados_proxy <-
as.numeric(c(t(dados_estacao[length(dados_estacao$DataHora):1, 16:46])))Em seguida fazemos um dataframe vazio, contendo 3 colunas. A primeira possui o código da estação sendo avaliado (como repete para todas as linhas, podemos pegar apenas o primeiro valor). A segunda as datas e a última sendo a coluna com os dados de vazão que está, por hora, vazio.
tabela_final <- data.frame(Cod_estacao = dados_estacao$EstacaoCodigo[1],
Data = Data_proxy,
Vazao = Dados_proxy)Agora temos que retirar todas as linhas desse data.frame que estão como formato NA, pois são as datas fictícias criadas por a gente e que de fato não existem (lembram que para criar o vetor Data_proxy nós criamos os dias 1 a 31 de todos os meses?). Portanto retiramos (usando o símbolo de “-”) essas linhas da nossa tabela_final.
Ainda temos um grande problema nessa situação. Existem casos em que uma estação não terá dados de um mês inteiro. Nesses casos não haverá linha para criarmos as datas fictícias. Portanto, para garantir que a nossa série estará com TODAS as datas, fazemos uma sequência que começa da menor data em nossa tabela e vai até a maior. Em seguida vemos quais as datas faltantes na nossa tabela e, caso existam essas datas faltantes, completamos nossa tabela. Isso é feito criando um data.frame com as mesmas colunas (Cod_estacao, Data e Dados) e depois juntando ambas tabelas com a função rbind. Como essas datas não foram coletadas informações a respeito das vazões (ou cotas), preenchemos a tabela com os dados sendo NA.
# Preencher as datas faltantes
datas_completas <-
seq.Date(from = min(tabela_final$Data),
to = max(tabela_final$Data),
by = "day")
datas_faltantes <-
datas_completas[!(datas_completas %in% tabela_final$Data)]
# Só rodar se tiver datas faltantes
if(length(datas_faltantes) != 0){
tabela_faltante <-
data.frame(Cod_estacao = cod_estacao,
Data = datas_faltantes,
Vazao = NA)
tabela_final <- rbind(tabela_final, tabela_faltante)
}Por fim colocamos essa tabela_final na ordem correta das datas (quando colamos com o rbind a ordem não fica como queremos) e pronto! Agora podemos ver, por exemplo, as primeiras 5 medições que não são NA
tabela_final <- tabela_final[order(tabela_final$Data),]
head(tabela_final[!is.na(tabela_final$Vazao),]) Cod_estacao Data Vazao
12 60435000 1978-05-12 2.5342
13 60435000 1978-05-13 2.5004
14 60435000 1978-05-14 2.5004
15 60435000 1978-05-15 2.4667
16 60435000 1978-05-16 2.4667
17 60435000 1978-05-17 2.5004Assim como feito nas outras etapas, podemos aqui fazer uma função para automatizar tudo que foi feito em várias etapas para deixar o processo mais automatizado e mais fácil quando quiser rodar o mesmo processo para outras estações.
dados_serie_ANA <- function(cod_estacao = NA,
data_inicio = "01/01/1800",
data_fim = Sys.Date(),
tipo_dados = 3,
nivel_consist = 1){
# Puxar dados do url e transformar em dataframe
url_base <- paste0("http://telemetriaws1.ana.gov.br/ServiceANA.asmx/",
"HidroSerieHistorica?",
"codEstacao=", cod_estacao,
"&dataInicio=", data_inicio,
"&dataFim=", data_fim,
"&tipoDados=", tipo_dados,
"&nivelConsistencia=", nivel_consist)
url_parse <- XML::xmlParse(url_base, encoding = "UTF-8")
node_doc <- XML::getNodeSet(url_parse, "//SerieHistorica")
dados_estacao <- XML::xmlToDataFrame(nodes = node_doc)
# Criamos datas fictícias com base nas linhas do arquivo XML da ANA
Data_proxy <-
as.Date(c(sapply(length(dados_estacao$DataHora):1, FUN = function(x){
paste0(as.character(format(as.Date(dados_estacao[x, 3]), "%Y-%m")),
"-",1:31)})))
# Puxamos os dados de vazão com a transposta de cada linha (colunas 16-46)
Dados_proxy <- as.numeric(c(t(dados_estacao[length(dados_estacao$DataHora):1, 16:46])))
# É feito um dataframe só com datas e valores de vazão
tabela_final <- data.frame(Cod_estacao = dados_estacao$EstacaoCodigo[1],
Data = Data_proxy,
Vazao = Dados_proxy)
# Retira-se as datas com valores NA
tabela_final <- tabela_final[-which(is.na(tabela_final$Data)),]
# Preencher as datas faltantes
datas_completas <- seq.Date(from = min(tabela_final$Data),
to = max(tabela_final$Data),
by = "day")
datas_faltantes <- datas_completas[!(datas_completas %in% tabela_final$Data)]
# Só rodar se tiver datas faltantes
if(length(datas_faltantes) != 0){
tabela_faltante <- data.frame(Cod_estacao = cod_estacao,
Data = datas_faltantes,
Vazao = NA)
tabela_final <- rbind(tabela_final, tabela_faltante)
}
# Ordem correta
tabela_final <- tabela_final[order(tabela_final$Data),]
# O que é retornado pela função
return(tabela_final)
}Para testar essa função basta utilizar a linha abaixo.
dados_60435000 <- dados_serie_ANA(cod_estacao = 60435000)
dados_60435000[10:15,] Cod_estacao Data Vazao
10 60435000 1978-05-10 NA
11 60435000 1978-05-11 NA
12 60435000 1978-05-12 2.5342
13 60435000 1978-05-13 2.5004
14 60435000 1978-05-14 2.5004
15 60435000 1978-05-15 2.4667Salvar arquivos
Salvar um arquivo único
Uma etapa tão importante quanto baixar os próprios dados que se precisa é conseguir salvar eles antes ou depois de alguma manipulação feita. Isso pode ser feito pelo R utilizando as funções write.table(), write.csv() ou variações delas - da mesma forma que haviam variações em read.table() read.csv().
Uma boa prática é deixar todos os argumentos mais importantes explícitos, para que não tenha dúvidas de qua função usar ou como se irá salvar. Assim deixa-se explícito abaixo o separador (tab), os decimais (“.”), que não irá salvar o nome das linhas (elas não tem nome) e a codificação do arquivo (acentos e etc.).
write.table(x = dados_60435000,
file = "dados_60435000.txt",
sep = "\t",
dec = ".",
row.names = FALSE,
fileEncoding = "UTF-8")Salvar em um loop
A vantagem de utilizar funções e automatizações é fazer tudo que foi feito acima para n estações, não apenas uma! Selecionamos já 4 estações de uma mesma bacia para fazermos análises mais a frente. Os códigos delas são:
- 60435000 (feita);
- 60436000;
- 60436190;
- 60443000 (última estação).
Para fazer isso, podemos rodar a nossa funão criada, dados_serie_ANA(), para cada uma dessas estações. Depois de rodar a função, podemos rodar também o código para salvar elas! Note que o i interno ao for() não precisa ser uma sequência, ele apenas informa quais os valores que i vai tomar a cada iteração. Na hora de salvar usamos a função paste0() pois o nome vai variar com cada iteração.
for(i in c(60435000, 60436000, 60436190, 60443000)){
dados_proxy <- dados_serie_ANA(i)
write.table(x = dados_proxy,
file = paste0(i, ".txt"),
sep = "\t",
dec = ".",
row.names = FALSE,
fileEncoding = "UTF-8")
}Agora temos 4 arquivos, um para cada estação que definimos, salvos em formato .txt do jeito que queremos - o que tornará a próxima etapa de manipulação muito mais fácil. Ao invés de termos um arquivo para cada estação com 78 colunas e as vazões podendo estar em diferentes linhas e colunas temos uma tabela bem simples, com apenas 3 colunas. Uma contendo o código da estação, outra a data e a última o valor de vazão observado. Se quisermos fazer um loop para salvarmos os 4 arquivos em um mesmo data.frame também podemos o fazer. Segue abaixo esse último exemplo.
estacoes <- c(60435000, 60436000, 60436190, 60443000)
for(i in 1:4){
# Qual estação estamos avaliando nesse loop específico
estacao_proxy <- estacoes[i]
# Rodar a função criada
dados_proxy <- dados_serie_ANA(estacao_proxy)
# Juntar as estações em uma só
if(i == 1) todas_estacoes <- dados_proxy
if(i != 1) todas_estacoes <- rbind(todas_estacoes, dados_proxy)
}
write.table(x = todas_estacoes,
file = "todas_estacoes.txt",
sep = "\t",
dec = ".",
row.names = FALSE,
fileEncoding = "UTF-8")